Apache Spark on AWS Lambda
最近在研究如何在AWS上构建Spark计算平台,它需要具有以下功能:
- 计算资源即拿即用
- 计算资源自动回收
- 计算资源动态伸缩
AWS官方提供的解决方案是使用Amazon EMR服务:
Amazon EMR 提供的托管 Hadoop 框架可以让您快速轻松、经济高效地在多个动态可扩展的 Amazon EC2 实例之间处理大量数据。您还可以运行其他常用的分布式框架 (例如 Amazon EMR 中的 Apache Spark、HBase、Presto 和 Flink),以及与其他 AWS 数据存储服务 (例如 Amazon S3 和 Amazon DynamoDB) 中的数据进行交互。
Amazon EMR 能够安全可靠地处理广泛的大数据使用案例,包括日志分析、Web 索引、数据转换 (ETL)、机器学习、财务分析、科学模拟和生物信息。


但是经我调研发现,Amazon EMR其实就是使用EC2帮助用户建立和维护一套Hadoop集群。至于资源的autoscale,则是通过EC2 Auto Scaling Group实现。这实际还是需要先为Spark建立一个计算资源池,只不过这个池是可以动态伸缩的。而我设想的理想方案是Spark只需运行一个Master/Scheduler节点,所有计算资源都可从一个公有资源池获取(比如AWS、腾讯云、阿里云等公有云),用户只需为计算任务使用到的计算资源付费。
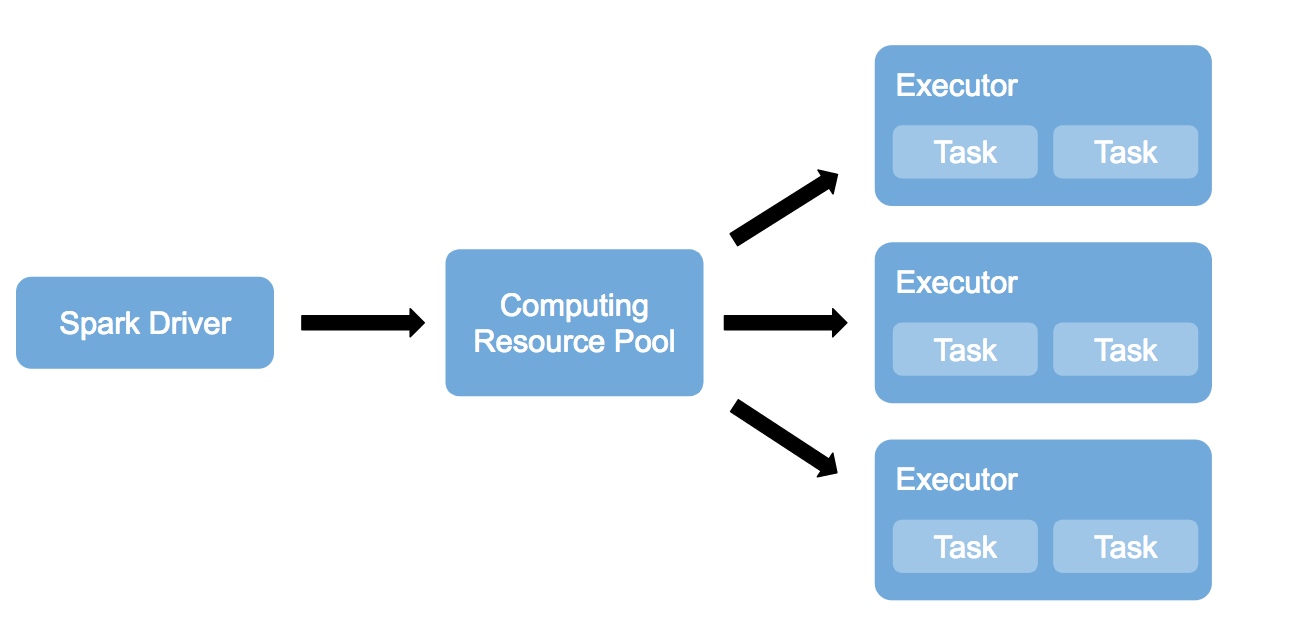
这种场景正好适用于AWS Lambda的Serverless架构:
通过 AWS Lambda,无需配置或管理服务器即可运行代码。您只需按消耗的计算时间付费 – 代码未运行时不产生费用。
借助 Lambda,您几乎可以为任何类型的应用程序或后端服务运行代码,而且全部无需管理。只需上传您的代码,Lambda 会处理运行和扩展高可用性代码所需的一切工作。您可以将您的代码设置为自动从其他 AWS 服务触发,或者直接从任何 Web 或移动应用程序调用。
而AWS Lambda的以下特点,正好完美满足我的业务需求:
- 更细粒度的计算资源分配
- 基本无需预先计划计算资源
- 高度弹性可扩展
- 按需使用,按使用量付费
不过遗憾的是,目前AWS并未给出Spark on AWS Lambda的官方解决方法。而网上几乎没有相关资料,只有Qubole提出的spark-on-lambda开源项目看似可行。
它的原理是:
- 使用Python Lambda function创建一个AWS Lambda funciton
- 创建后,Python代码会从S3上下载Spark libraries,解压到/tmp,并通过Java启动Spark Executor
- 这个Executor会给Spark Driver发送心跳,并加入到Spark application
为此,Qubole还专门实现了一个新的Spark Scheduler。
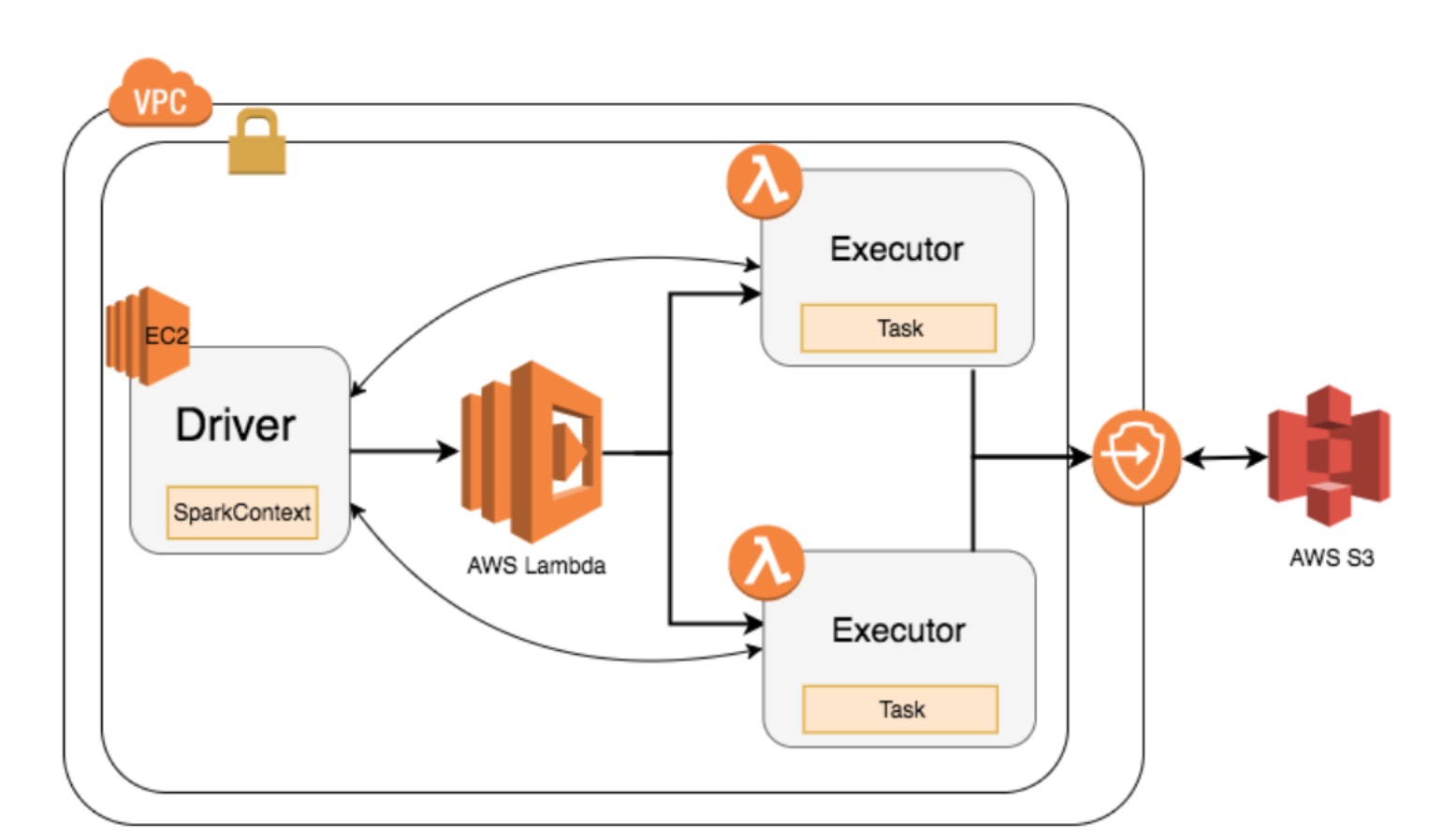
不过此方案目前还远未成熟,其中涉及的很多关键问题还亟待解决,比如:
- AWS Lambda的执行时间只有5分钟
- AWS Lambda不允许Lambda function之间相互通信
- AWS Lambda只能提供最多1536MB内存和512MB的磁盘空间
结论
由于AWS Lambda的诸多限制,Apache Spark on AWS Lambda还未有成熟可生产的解决方案,不过Apache Spark on Serverless这种架构倒是值得在私有云中探索。
参考资料
Qubole Announces Apache Spark on AWS Lambda Lambda Architecture Lambda Function Handler (Python) Lambda Architecture with Apache Spark