最近在上海参加 Kubecon,通过交流和 session 使我对资源共享和混部有了些新的想法。先零散的记录下来,后续再整理成可行的方案和方法论。
现状
目前我们大数据平台的资源管理和调度都是基于 Kubernetes 的。我们将大数据任务分为 Routine Job 和 Batch Job 两种类型(而实际上我们的混部方案要比这复杂,还包括 HDFS 和在线业务,在此先不表)。Routine Job 运行在独占资源池上,通过 namespace 划分,维度可能是小组、部门或项目。我们需要优先保证此类 Job 的可用资源,它需要较高的 SLA 和 较小的 RT。一般来说,我们会根据实际物理资源去划分独占资源池。这类 Job 对资源的消耗比较固定。第二种任务是 Batch Job,它具有较低的 Priority,可以容忍较低的 SLA 和 较高的 RT。Batch Job 对资源的需求是动态和较难估计的。
由于我们自己 IDC 的资源有限,我们希望可以用更少的机器运行更多的 Job(从某个角度上来说,也是为了提升 machine utilization),resource sharing 是一个好的选择。当然还有另一种选择是将动态资源池 offload 到云上,这样可以用最简单的方案实现资源的即拿即用。但由于国内网络环境和数据安全的考虑,该方案只被用于沙箱环境。
关键技术
若想实现 resource sharing,我们至少需考虑两个问题(实际远不止这么多):
- 独占资源如何回收再分配
- 独占资源如何保障可用性
资源回收和再分配
针对第一个问题,我的想法是实现一种资源回收机制(当然借鉴了其它成熟的调度系统),它可以定期根据 Job 的实际资源使用率估算出资源消耗,回收这部分 gap 的资源分配给 Batch Job 使用。我们姑且将此过程称之为 Resource Reclamation,估算资源消耗的过程称为 Resource Consumption Prediction。计算资源消耗的算法最简单的方法是以现有资源消耗加一个 margin。
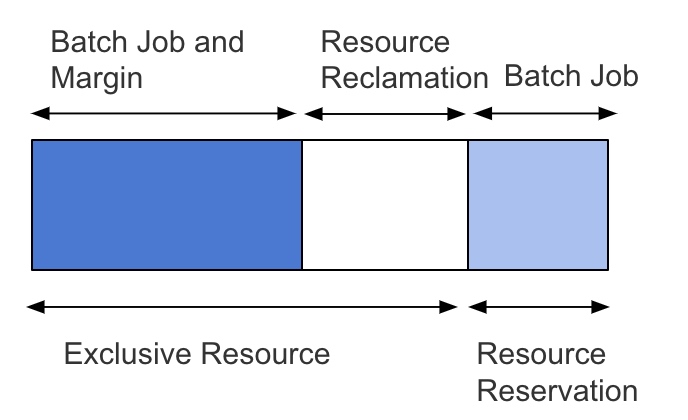
Exclusive Resource + Resource Reservation = Physical Machine Resource。在 Kubernetes 中,我们可以通过 Namespace Quota 定义总的 Exclusive Resource Pool,并为 Kubelet 设置 System Reservation。至于 Resource Consumption Prediction 可以通过诸如 cadvisor 或其他外部 Monitor 等手段采集计算。我们可以使用诸如 Kubernetes Operator 或者 client-go Informer 实现一个 Kubernetes Resource Reclamation Controller 定期执行以上过程。资源回收还有一个难点是回收的资源如何再分配给 Batch Job 使用。我目前估计只能修改 Kubernetes apiserver 和 scheduler,定期更新 NodeInfo 的 allocatableResource(具体实现方式还需我深入阅读相关源码后再做定夺)。
资源抢占
在多数时间段里,独占资源的实际使用是低于分配的,所以混部是提高资源使用率的有效手段。但是一旦遇到 workload spike 就需要将 Batch Job 占有的 overcommitting resource 还回去。这时可以利用诸如 Kubernetes Eviction & Preemption 等手段将 Batch Job Task 杀掉。因为一般在生产中,Routine Job 的 resource request 是等于 limit 的,这就意味着它具有最高级别的 Guaranteed QoS。而 Batch Job 我们只会设置它的一个 limit 上限,也就是 Burstable QoS。在资源紧张时,Kubernetes 会优先杀掉 Burstable Pod,将之还回 scheduler queue,以待重新调度。实际也只有诸如 exceeded memory 这种情况出现时,会驱逐 Burstable Pod。cpu 的话一般会 throttle 一下,这并不会对相应的 Job 造成很大干扰。
暂时的最后
实际上混部是一个比较复杂的、一整套的解决方案,它可能包括:评估模型(Evaluation methodology)、资源回收、资源监控、资源预估、资源再分配、资源调度、资源隔离和资源驱逐抢占等技术。而且中间掺杂着大量经验数据,这些均需通过以往集群的 utilization 和 workload 数据,结合实际业务需求进行分析 -》 制定解决方案 -》实施 -》再分析,这个循环。
由于时间紧张,以上只是我仓促间形成的一些小的想法,完全不保证可行性和正确性。过几天,我会再从理论层面整理和验证下。如果通过,我会实现一个 demo,供检验。
《未完待续》