Amazon S3是Amazon公司提供的对象存储服务,可从任意位置存储和检索任意数量的数据。Amazon S3是目前最受欢迎的存储平台。
我们可以使用S3作为数据源,并为运行在AWS EC2中的Hadoop集群配置S3访问。
目前在Hadoop 2.7+种,建议的访问方式为:S3A (URI Scheme: s3a://)。相比之前Hadoop访问S3的方式(S3N和S3),S3A使用Amazon实现的访问库和S3通信,这使得S3A可支持更大的文件(没有5GB的限制)和更高的性能等。
配置S3A
配置EC2的S3访问权限
若想使得EC2访问S3,有两种方式:
- 通过AWS IAM Role
- 通过Access Key ID & Key
AWS IAM Role
首先创建AWS IAM Role,为Role选择EC2作为trusted entity:
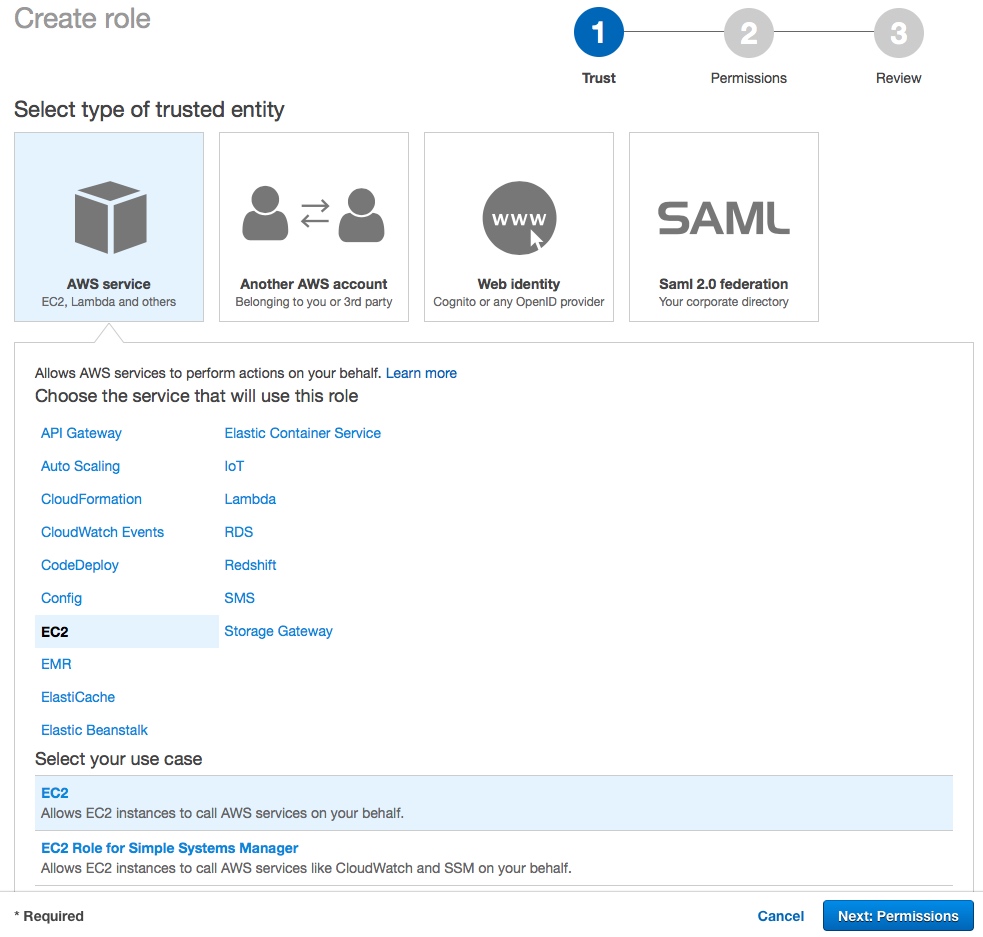
接下来创建Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws-cn:s3:::{your-own-bucket}",
"arn:aws-cn:s3:::{your-own-bucket}/*"
]
}
]
}
然后在启动EC2实例时指定Role:
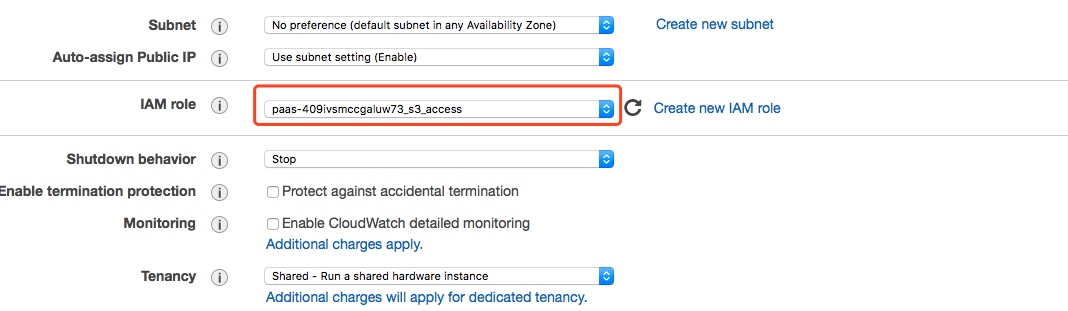
进入EC2实例进行测试:
# aws configure
AWS Access Key ID [None]:
AWS Secret Access Key [None]:
Default region name [cn-north-1]: cn-north-1
# aws s3 ls s3://test/
PRE test2/
2017-12-27 16:07:38 20 test.txt
S3 Access Key ID & Key
此方式和以上类似,主要区别在于需先创建IAM User,然后建立访问S3的Policy,把User和Policy关联,最后为User新建一个Securiy credentials:
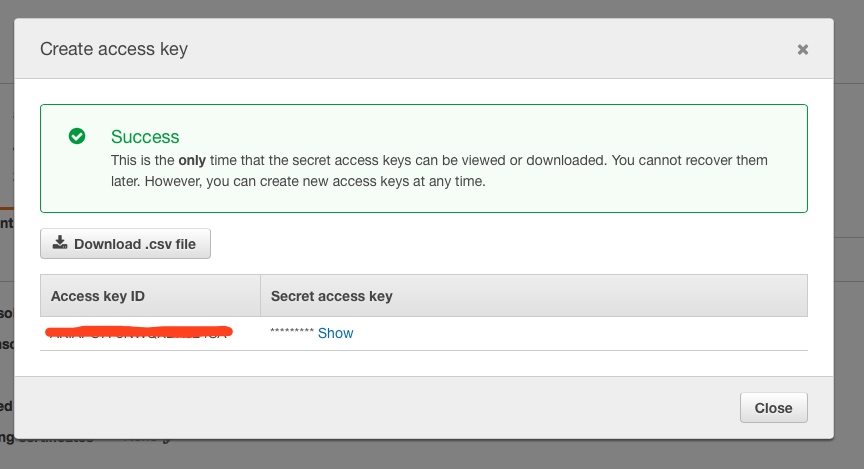
记录Key ID和Key,在Hadoop的配置中需要用到。
配置Hadoop访问S3
修改hadoop/etc/hadoop/core-site.xml,添加以下配置:
<property>
<name>fs.s3.awsAccessKeyId</name>
<description>AWS access key ID</description>
</property>
<property>
<name>fs.s3.awsSecretAccessKey</name>
<description>AWS secret key</description>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>s3.cn-north-1.amazonaws.com.cn</value>
</property>
若使用Access Key ID & Key访问S3,则需要配置fs.s3.awsAccessKeyId和fs.s3.awsSecretAccessKey。
最后为Hadoop访问S3引入依赖包:
cp hadoop/share/hadoop/tools/lib/hadoop-aws-2.7.3.jar hadoop/share/hadoop/common/lib/
cp hadoop/share/hadoop/tools/lib/aws-java-sdk-1.7.4.jar hadoop/share/hadoop/common/lib/
cp hadoop/share/hadoop/tools/lib/joda-time-2.9.4.jar hadoop/share/hadoop/common/lib/
cp hadoop/share/hadoop/tools/lib/jackson-*.jar hadoop/share/hadoop/common/lib/
至此配置完成,可通过hdfs进行测试:
$ hdfs dfs -ls s3a://test/
Found 2 items
-rw-rw-rw- 1 20 2017-12-27 16:07 s3a://test-hadoop/test.txt
drwxrwxrwx - 0 1970-01-01 08:00 s3a://test-hadoop/test2
如何通过Spark访问S3
由于Hadoop集群中已经配置了S3访问,所以在Spark中只需使用S3A直接访问即可:
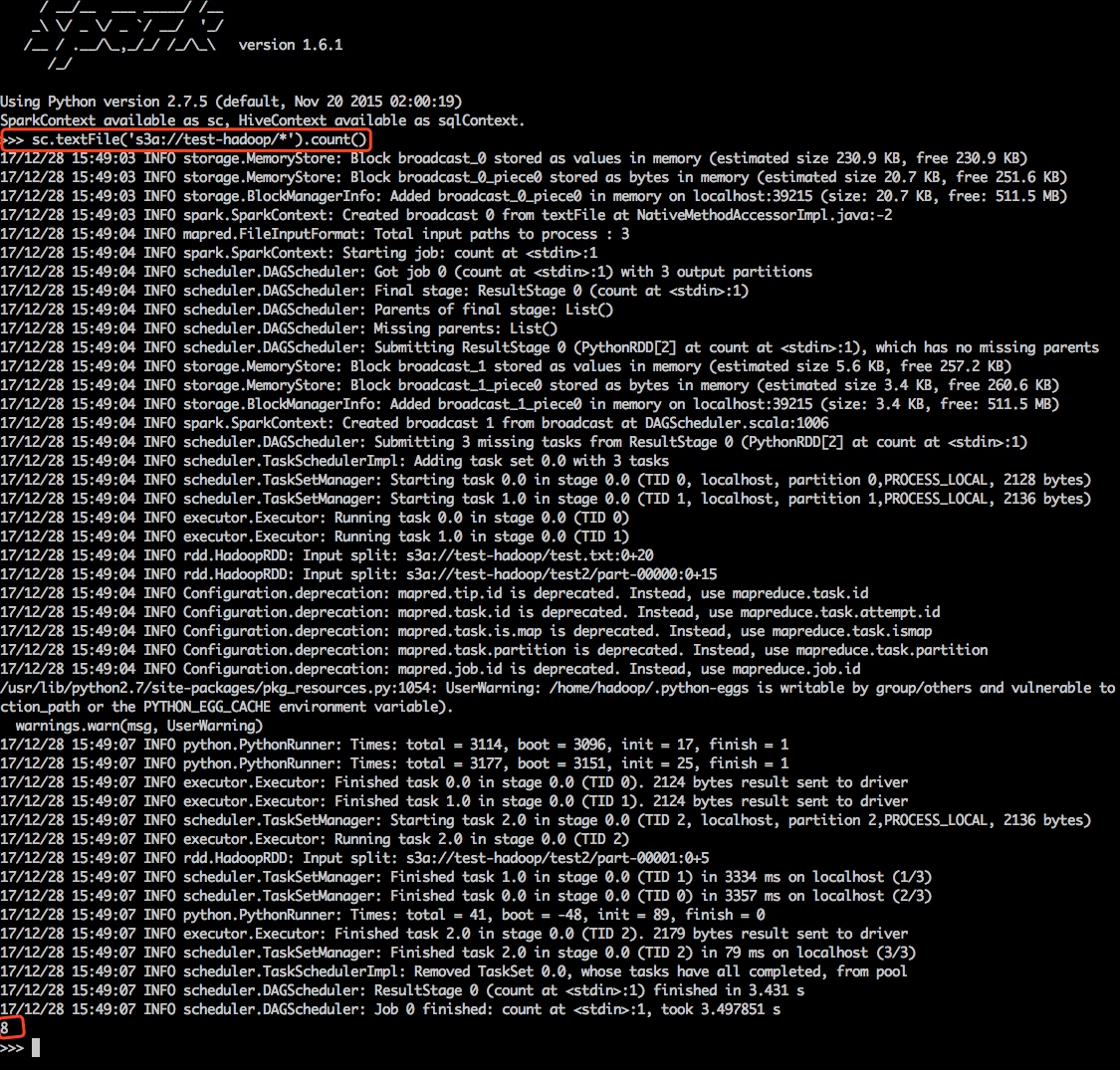
向S3写数据:

S3的批量拷贝操作
我们可以通过hadoop distcp命令批量在HDFS和S3之间批量拷贝数据:
$ hadoop distcp hdfs://xxx:9001/user/test/xxxx s3a://test/
注意事项
S3并不是HDFS的替代品。HDFS本质上是文件系统,而S3则是对象存储。和文件系统相比,它有以下区别:
- 对数据的操作无法保证实时性,而只保证最终一致性
- s3n和s3a的
rename和delete不是原子操作。在对大量文件夹进行删除和重命名操作时,操作时间取决于object数量,并且此过程对其他操作是可见的,操作结果只保证最终一致性。
S3不是一种文件系统,Hadoop S3 filesystem接口只是将S3模拟成文件系统。它可以作为数据源,并作为数据结果集输出,但是输出结果可能不会立刻可见。