如何使用 Kubernetes VPA 实现资源动态扩展和回收
简述
最近一段时间在研究和设计集群资源混合部署方案,以提高资源使用率。这其中一个重要的功能是资源动态扩展和回收。虽然方案是针对通用型集群管理软件,但由于 Kubernetes 目前是事实标准,所以先使用它来检验理论成果。
资源动态扩展
资源动态扩展按照类型分为两种:纵向和横向。纵向指的是对资源的配置进行扩展,比如增加或减少 CPU 个数和内存大小等。横向扩展则是增加资源的数量,比如服务器个数。笔者研究方案的目的是为了提升集群资源使用率,所以这里单讨论资源纵向扩展。
不过坦白来讲,资源纵向扩展首要目标并不是为了提高集群利用率,而是为了优化集群资源、提高资源可用性和性能。
在 Kubernetes 中 VPA 项目主要是完成这项工作(主要针对 Pod)。
Kubernetes VPA
Vertical Pod Autoscaler (VPA) frees the users from necessity of setting up-to-date resource requests for the containers in their pods. When configured, it will set the requests automatically based on usage and thus allow proper scheduling onto nodes so that appropriate resource amount is available for each pod.
以上是官方定义。简单来说是 Kubernetes VPA 可以根据实际负载动态设置 pod resource requests。
Kubernetes VPA 包含以下组件:
- Recommender:用于根据监控指标结合内置机制给出资源建议值
- Updater:用于实时更新 pod resource requests
- History Storage:用于采集和存储监控数据
- Admission Controller: 用于在 pod 创建时修改 resource requests
以下是架构图:
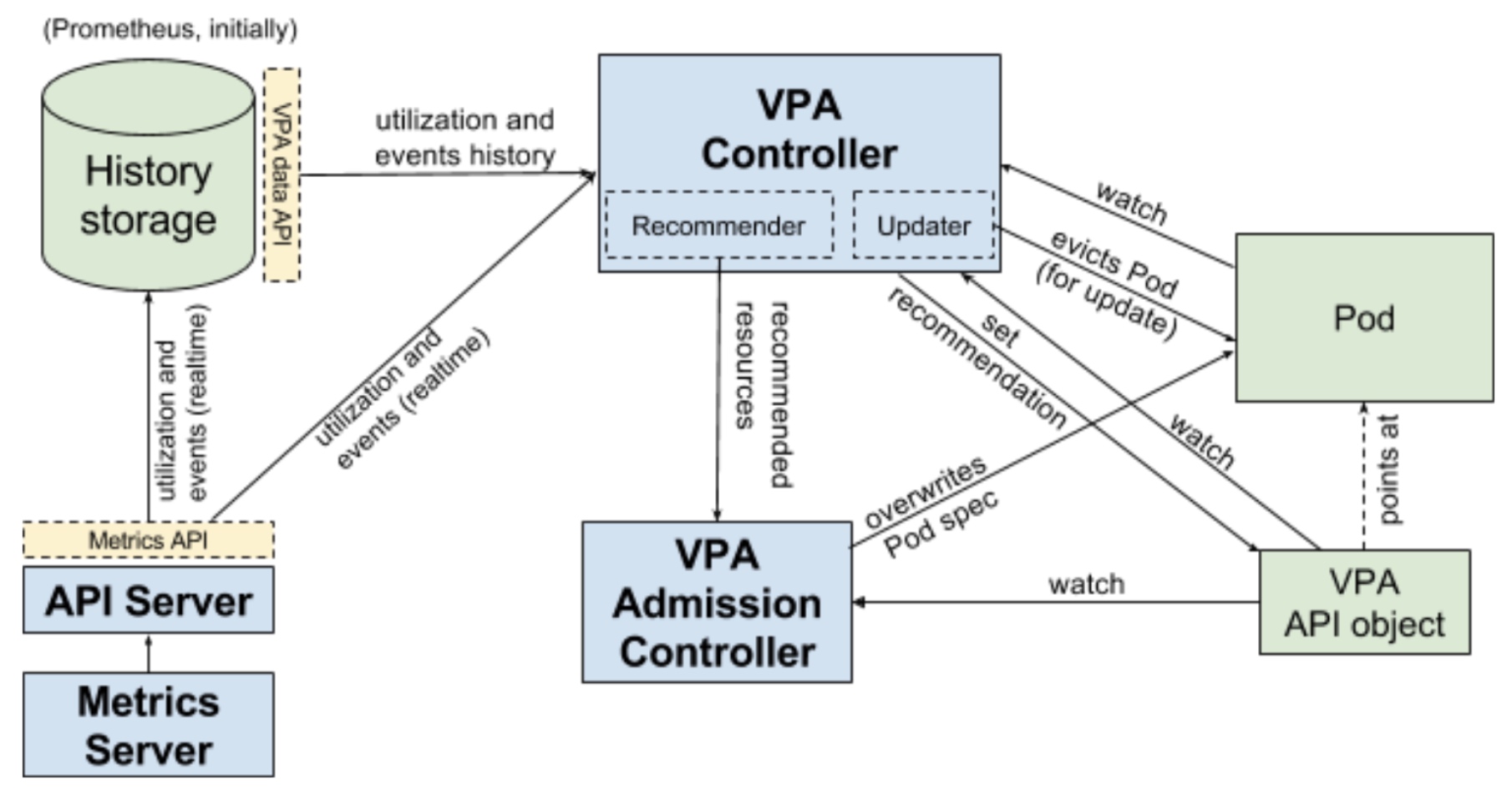
主要流程是:Recommender在启动时从History Storage获取历史数据,根据内置机制修改VPA API object资源建议值。Updater监听VPA API object,依据建议值动态修改 pod resource requests。VPA Admission Controller则是用于 pod 创建时修改 pod resource requests。History Storage则是通过Kubernetes Metrics API采集和存储监控数据。
Kubernetes VPA 的整体架构比较简单,流程也很清晰,理解起来并不困难。但里面隐藏的几个功能点,却是方案的核心所在。它们的质量直接影响了方案的成熟度和评价效果:
1、如何设计 Recommendation model
Recommendation model是集群优化的重中之重,它的好坏直接影响了集群资源优化的效果。就笔者目前了解,在 Kubernetes VPA 中这个模型是固定的,用户能做的是配置参数和数据源。
从官方描述看:
The request is calculated based on analysis of the current and previous runs of the container and other containers with similar properties (name, image, command, args). The recommendation model (MVP) assumes that the memory and CPU consumption are independent random variables with distribution equal to the one observed in the last N days (recommended value is N=8 to capture weekly peaks). A more advanced model in future could attempt to detect trends, periodicity and other time-related patterns.
CPU 和内存的建议值均是依据历史数据+固定机制计算而成,并没有一套解释引擎能让用户自定义规则。这在一定程度上影响了Recommendation model的准确性。就笔者理解,集群优化和混合部署的核心难点在于寻找能准确描述集群负载的指标,建立指标模型,并最终通过优化模型而达到最终目的 - 不论是为了优化集群或提高集群使用率。这个过程类似机器学习:先依旧经验或特征工程寻找特征变量,建立模型后使用数据不断优化参数,最后得到可用模型。所以仅靠单一指标 - 比如 CPU 或内存使用率 - 所建立的固定模型并不能准确描述集群状态和资源瓶颈。不管是从指标的颗粒度或固定模型上来看,最终效果都不会太好。
2、Pod 是否支持热更新
在 Kubernetes 中,pod resource requests 会影响 pod QoS 和容器的限制状态,比如驱逐策略、OOM Score和 cgroup 的限制参数等。如果不重建的话,单纯的修改 pod spec 只会影响调度策略。重建的话会导致 pod 重新调度,同时也在一定程度上降低了应用的可用性。官网列出一个更新策略auto,是可以in-place重建:
“Auto”: VPA assigns resource requests on pod creation as well as updates them on existing pods using the preferred update mechanism. Currently this is equivalent to “Recreate” (see below). Once restart free (“in-place”) update of pod requests is available, it may be used as the preferred update mechanism by the “Auto” mode. NOTE: This feature of VPA is experimental and may cause downtime for your applications.
目前应该没有完全实现。不过无论哪种方式,pod 重建貌似不可避免。
3、Pod 实时更新是否支持模糊控制
由于 Pod 更新会涉及重建,那么实时更新的触发条件就不应依据一个固定的值,比如值的变化触发更新重建(显然不可取)、依据逻辑表达式触发更新重建(也不可取,极端情况下会在设定值上下不断触发)。此时就需要在离散的值之间加入缓冲范围。而这个范围的设置高度依赖经验和实际集群情况,不然的话又会影响方案的最终效果。
总的来说,Kubernetes VPA 解决了资源纵向扩展的大部分工程问题。若应用于生产,还需做很多的个性化工作。
资源回收
既然 Kubernetes VPA 主要目标不是提升资源使用率,那它和混合部署又有何关系?别急,我们先来回顾下集群混合部署中提升资源使用率的关键是什么。
提升资源使用率最直观的方式,是在保证服务可用性的前提下尽量多的分配集群资源。我们知道在一般的集群管理软件中,调度器会为应用分配集群的可用资源。分配给应用的是逻辑资源,无需要和物理资源一一对应,比如可以超卖。并且应用持有的资源,一般情况下也不会全时段占用。在这种情况下,可将分配资源分为闲时和忙时。应用按照优先级区分,为高优先级的应用分配较多的资源。动态回收高优先级应用的闲时资源分配给低优先级应用使用,在高优先级应用负载升高时驱逐低优先级应用,从而达到提升资源使用率的目的。
在 Kubernetes VPA 中缺少资源回收的机制,但Recommender却可以配合Updater动态修改 pod resource requests 的值。也就是说 pod resource requests - 推荐值 = 资源回收值。这间接实现了资源回收的功能。那么 Kubernetes 调度器就可将这部分资源分配给其他应用使用。当然实际方案不会这么简单。比如Recommender就不需要使用History Storage中的历史数据和计算规则。初始值设为 pod resource requests,实时获取监控数据,加个 buffer 即可。这可以算是 Kubernetes 简陋版的资源回收功能。至于回收后,资源再分配和资源峰值驱逐等又是另一套流程了。
总结
暂时还是打算基于 Kubernetes VPA 实现资源回收和混合部署功能,毕竟现成的轮子。至于集群负载指标和模型,就完全是一套经验工程了。只能在实际生产中慢慢积累,别无他法。