Linux 的 I/O 模型以及 Go 的网络模型实现
第一部分:Linux 的 I/O 模型
在 Linux 中有五种基本的 I/O 模型,它们分别是:
- blocking I/O
- nonblocking I/O
- I/O multiplexing (select、poll和epoll)
- signal driven I/O
- asynchronous I/O
注:由于 signal driven I/O 在实际应用中较少,所以在此我只会简单介绍其他四种模型。
前言
在 I/O 流程中,一般分为两个不同的阶段:
- 数据等待阶段。该阶段是在等待接受网络数据,一旦网络设备收到数据包,内核将会把包拷贝到内核缓冲区
- 数据拷贝阶段。该阶段的数据包会被从内核缓冲区拷贝到应用缓冲区
通过以上对流程阶段的定义,又可将 I/O模型分为 synchronous I/O 和 asynchronous I/O:
- synchronous I/O 会 block 请求进程,直到 I/O 操作完成。不论这个 block 是发生在数据等待阶段还是数据拷贝阶段
- asynchronous I/O 不会 block 请求进程
所以依据定义,blocking I/O、nonblocking I/O、I/O multiplexing( select、poll和epoll )都是属于 synchronous I/O,因为它们都会在数据拷贝阶段 block 进程。
Synchronous I/O
Blocking I/O
在 Linux 中,默认的所有 socket 都是 blocking 的,一个典型的读操作流程如下:
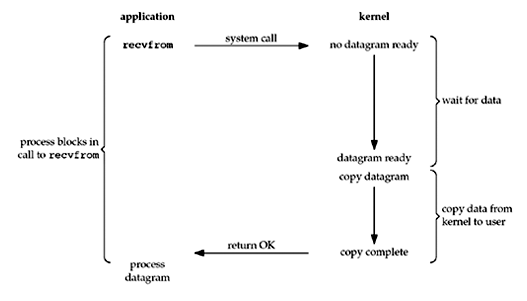
简单的说 blocking I/O 在数据准备和拷贝阶段都是 block 进程的。
Nonblocking I/O
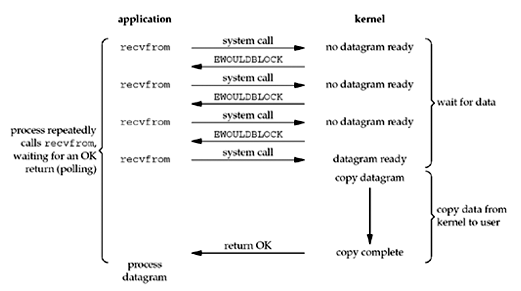 可以将 socket 设置为 nonblocking,这会使得内核在无数据时返回 error,而不是 block 请求进程。如果有数据,在数据拷贝阶段
可以将 socket 设置为 nonblocking,这会使得内核在无数据时返回 error,而不是 block 请求进程。如果有数据,在数据拷贝阶段recvfrom还是会 block 进程。
I/O Multiplexing
I/O Multiplexing 实际上是一种 I/O 复用技术,它使得单个进程可以管理多个网络连接。在 Linux 中,通常有 select、poll 和 epoll 这几种方式。
Select/Poll
Select/poll 会不断轮询所有负责的 socket( socket 会被设置成 nonblocking ),直到某个 socket 有数据就返回。它的基本流程是:
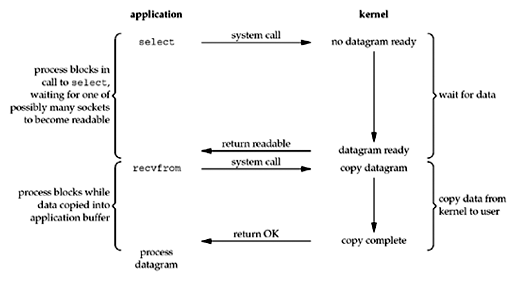 我们的操作实际上 block 在调用 select/poll 的函数里,而不是 block 在数据准备阶段。以下示例代码可以清楚的说明该流程:
我们的操作实际上 block 在调用 select/poll 的函数里,而不是 block 在数据准备阶段。以下示例代码可以清楚的说明该流程:
while(1){
FD_ZERO(&rset);
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset);
}
puts("round again");
select(max+1, &rset, NULL, NULL, NULL); // 等待数据返回
for(i=0;i<5;i++) {
if (FD_ISSET(fds[i], &rset)){
memset(buffer,0,MAXBUF);
read(fds[i], buffer, MAXBUF);
puts(buffer);
}
}
}
return 0;
}
Epoll
从以上示例代码可以看到,在每次调用 select 时都会将rset从用户空间拷贝到内核空间,并且在返回时,每次都需要遍历fds。为了避免以上问题,Linux 在2.6后引入了 epoll。epoll 实际上是在内核中维护了一个 context,它将以上任务分为了三步:
- 调用
epoll_create在内核中创建 context - 调用
epoll_ctl增加或删除 fd - 调用
epoll_wait等待事件发生
示例代码如下:
struct epoll_event events[5];
int epfd = epoll_create(10); // 创建 context
...
...
for (i=0;i<5;i++)
{
static struct epoll_event ev;
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
ev.data.fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
ev.events = EPOLLIN;
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev); // 添加 fd
}
while(1){
puts("round again");
nfds = epoll_wait(epfd, events, 5, 10000); // 等待数据返回
for(i=0;i<nfds;i++) {
memset(buffer,0,MAXBUF);
read(events[i].data.fd, buffer, MAXBUF);
puts(buffer);
}
}
这样的话 fd 只需在初始化时传递一次,并且在epoll_wait返回时也无需检查所有 fd。
由于无论是 select、poll 还是 epoll,它们都会 block 在recvfrom阶段,所以它们都称为 synchronous nonblocking I/O。
Asynchronous I/O
Asynchronous I/O 是真正在各个阶段都实现了 nonblocking。当请求进程发起读操作时,内核会立刻返回,所以不会阻塞请求进程。内核在数据准备完成后,会将数据拷贝到用户空间,当所有这些工作全部完成,内核会通知请求进程,告诉它读操作已完成。
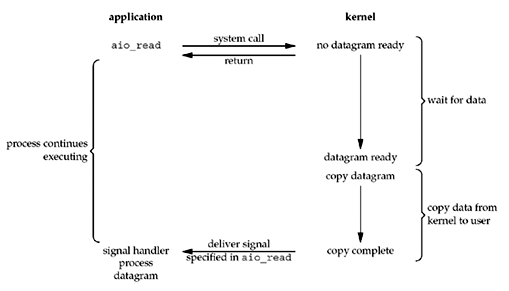
I/O 模型的比较
下图清楚说明了各个 I/O 模型的异同:
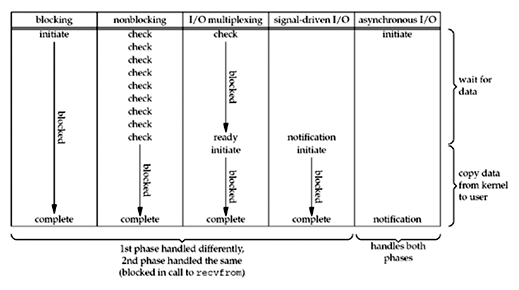
实际上,前四种模型的区别在于第一阶段,也就是数据准备阶段。在数据拷贝阶段,它们都是 block 进程的。而 Asynchronous I/O 在两个阶段均和以上四种模型不同。