Spark On Kubernetes实践
前言
众所周知,Spark是一个快速、通用的大规模数据处理平台,和Hadoop的MapReduce计算框架类似。但是相对于MapReduce,Spark凭借其可伸缩、基于内存计算等特点,以及可以直接读写Hadoop上任何格式数据的优势,使批处理更加高效,并有更低的延迟。实际上,Spark已经成为轻量级大数据快速处理的统一平台。
Spark作为一个数据计算平台和框架,更多的是关注Spark Application的管理,而底层实际的资源调度和管理更多的是依靠外部平台的支持:
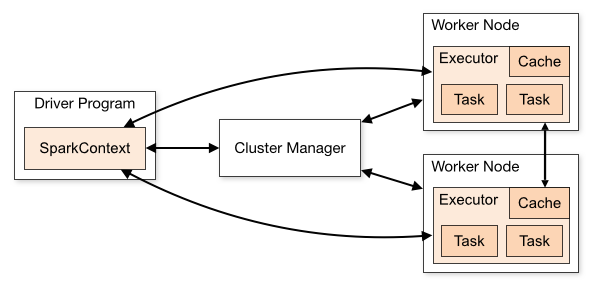
Spark官方支持四种Cluster Manager:Spark standalone cluster manager、Mesos、YARN和Kubernetes。由于我们TalkingData是使用Kubernetes作为资源的调度和管理平台,所以Spark On Kubernetes对于我们是最好的解决方案。
如何搭建生产可用的Kubernetes集群
部署
目前市面上有很多搭建Kubernetes的方法,比如Scratch、Kubeadm、Minikube或者各种托管方案。因为我们需要简单快速地搭建功能验证集群,所以选择了Kubeadm作为集群的部署工具。部署步骤很简单,在master上执行:
kubeadm init
在node上执行:
kubeadm join --token <token> <master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>
具体配置可见官方文档:https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
需要注意的是由于国内网络限制,很多镜像无法从k8s.gcr.io获取,我们需要将之替换为第三方提供的镜像,比如:https://hub.docker.com/u/mirrorgooglecontainers/。
网络
Kubernetes网络默认是通过CNI实现,主流的CNI plugin有:Linux Bridge、MACVLAN、Flannel、Calico、Kube-router、Weave Net等。Flannel主要是使用VXLAN tunnel来解决pod间的网络通信,Calico和Kube-router则是使用BGP。由于软VXLAN对宿主机的性能和网络有不小的损耗,BGP则对硬件交换机有一定的要求,且我们的基础网络是VXLAN实现的大二层,所以我们最终选择了MACVLAN。
CNI MACVLAN的配置示例如下:
{
"name": "mynet",
"type": "macvlan",
"master": "eth0",
"ipam": {
"type": "host-local",
"subnet": "10.0.0.0/17",
"rangeStart": "10.0.64.1",
"rangeEnd": "10.0.64.126",
"gateway": "10.0.127.254",
"routes": [
{
"dst": "0.0.0.0/0"
},
{
"dst": "10.0.80.0/24",
"gw": "10.0.0.61"
}
]
}
}
Pod subnet是10.0.0.0/17,实际pod ip pool是10.0.64.0/20。cluster cidr是10.0.80.0/24。我们使用的IPAM是host-local,规则是在每个Kubernetes node上建立/25的子网,可以提供126个IP。我们还配置了一条到cluster cidr的静态路由10.0.80.0/24,网关是宿主机。这是因为容器在macvlan配置下egress并不会通过宿主机的iptables,这点和Linux Bridge有较大区别。在Linux Bridge模式下,只要指定内核参数net.bridge.bridge-nf-call-iptables = 1,所有进入bridge的流量都会通过宿主机的iptables。经过分析kube-proxy,我们发现可以使用KUBE-FORWARD这个chain来进行pod到service的网络转发:
-A FORWARD -m comment --comment "kubernetes forward rules" -j KUBE-FORWARD
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
-A KUBE-FORWARD -s 10.0.0.0/17 -m comment --comment "kubernetes forwarding conntrack pod source rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A KUBE-FORWARD -d 10.0.0.0/17 -m comment --comment "kubernetes forwarding conntrack pod destination rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
最后通过KUBE-SERVICES使用DNAT到后端的pod。pod访问其他网段的话,就通过物理网关10.0.127.254。
还有一个需要注意的地方是出于kernel security的考虑,link物理接口的macvlan是无法直接和物理接口通信的,这就导致容器并不能将宿主机作为网关。我们采用了一个小技巧,避开了这个限制。我们从物理接口又创建了一个macvlan,将物理IP移到了这个接口上,物理接口只作为网络入口:
$ cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
IPV6INIT=no
BOOTPROTO=none
$ cat /etc/sysconfig/network-scripts/ifcfg-macvlan
DEVICE=macvlan
NAME=macvlan
BOOTPROTO=none
ONBOOT=yes
TYPE=macvlan
DEVICETYPE=macvlan
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPADDR=10.0.0.61
PREFIX=17
GATEWAY=10.0.127.254
MACVLAN_PARENT=eth0
MACVLAN_MODE=bridge
这样两个macvlan是可以互相通信的。
Kube-dns
默认配置下,Kubernetes使用kube-dns进行DNS解析和服务发现。但在实际使用时,我们发现在pod上通过service domain访问service总是有5秒的延迟。使用tcpdump抓包,发现延迟出现在DNS AAAA。进一步排查,发现问题是由于netfilter在conntrack和SNAT时的Race Condition导致。简言之,DNS A和AAAA记录请求报文是并行发出的,这会导致netfilter在_nf_conntrack_confirm时认为第二个包是重复的(因为有相同的五元组),从而丢包。具体可看我提的issue:https://github.com/kubernetes/kubernetes/issues/62628。一个简单的解决方案是在/etc/resolv.conf中增加options single-request-reopen,使DNS A和AAAA记录请求报文使用不同的源端口。我提的PR在:https://github.com/kubernetes/kubernetes/issues/62628,大家可以参考。我们的解决方法是不使用Kubernetes service,设置hostNetwork=true使用宿主机网络提供DNS服务。因为我们的基础网络是大二层,所以pod和node可以直接通信,这就避免了conntrack和SNAT。
Spark与Kubernetes集成
由于Spark的抽象设计,我们可以使用第三方资源管理平台调度和管理Spark作业,比如Yarn、Mesos和Kubernetes。目前官方有一个experimental项目,可以将Spark运行在Kubernetes之上:https://spark.apache.org/docs/latest/running-on-kubernetes.html。
基本原理
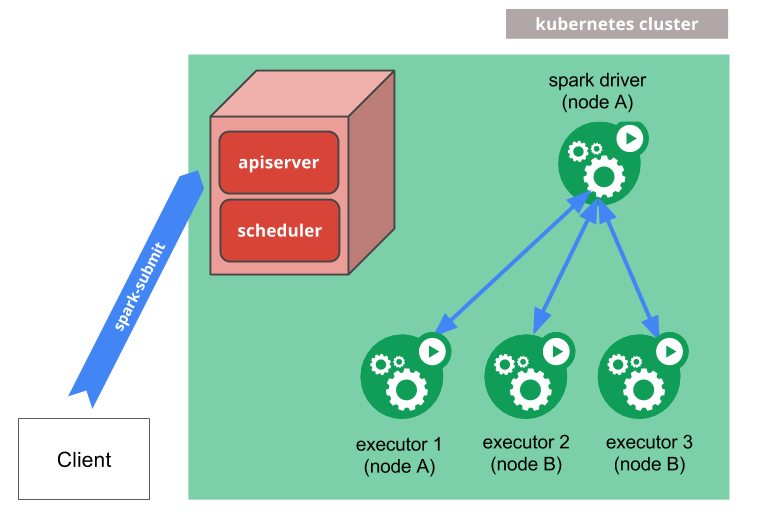 当我们通过
当我们通过spark-submit将Spark作业提交到Kubernetes集群时,会执行以下流程:
- Spark在Kubernetes pod中创建Spark driver
- Driver调用Kubernetes API创建executor pods,executor pods执行作业代码
- 计算作业结束,executor pods回收并清理
- driver pod处于
completed状态,保留日志,直到Kubernetes GC或者手动清理
先决条件
- Spark 2.3+
- Kubernetes 1.6+
- 具有Kubernetes pods的list, create, edit和delete权限
- Kubernetes集群必须正确配置Kubernetes DNS
如何集成
Docker镜像
由于Spark driver和executor都运行在Kubernetes pod中,并且我们使用Docker作为container runtime enviroment,所以首先我们需要建立Spark的Docker镜像。
在Spark distribution中已包含相应脚本和Dockerfile,可以通过以下命令构建镜像:
$ ./bin/docker-image-tool.sh -r <repo> -t my-tag build
$ ./bin/docker-image-tool.sh -r <repo> -t my-tag push
提交作业
在构建Spark镜像后,我们可以通过以下命令提交作业:
$ bin/spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--jars https://path/to/dependency1.jar,https://path/to/dependency2.jar
--files hdfs://host:port/path/to/file1,hdfs://host:port/path/to/file2
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
https://path/to/examples.jar
其中,Spark master是Kubernetes api server的地址,可以通过以下命令获取:
$ kubectl cluster-info
Kubernetes master is running at http://127.0.0.1:6443
Spark的作业代码和依赖,我们可以在--jars、--files和最后位置指定,协议支持http、https和hdfs。
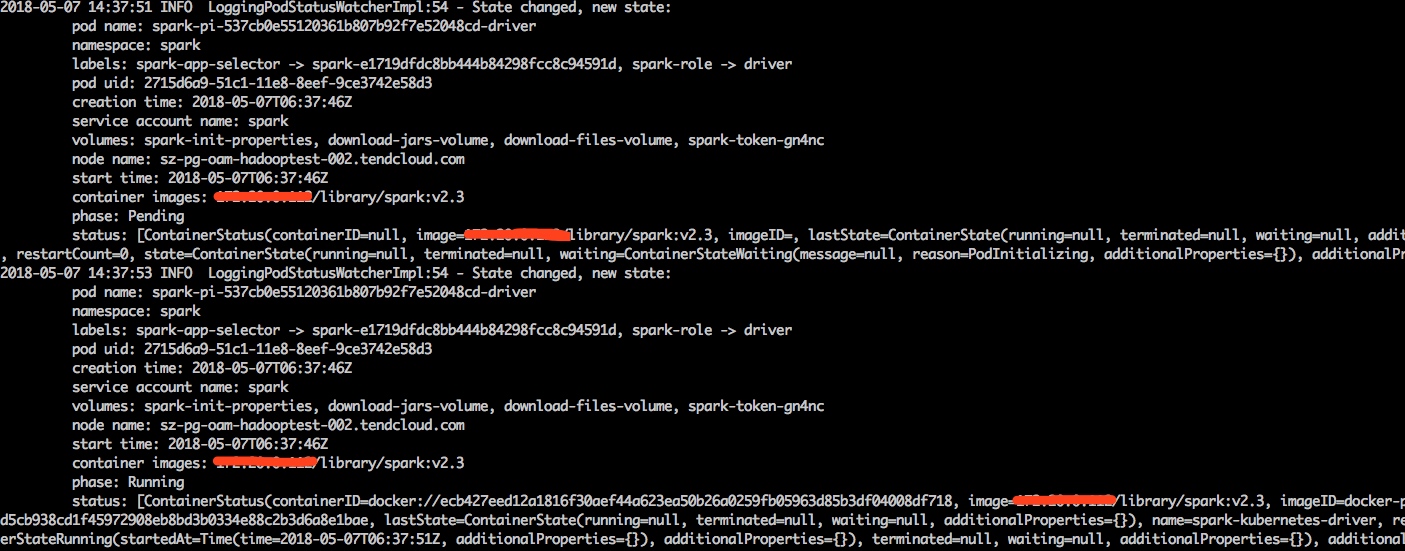
执行提交命令后,会有以下输出:
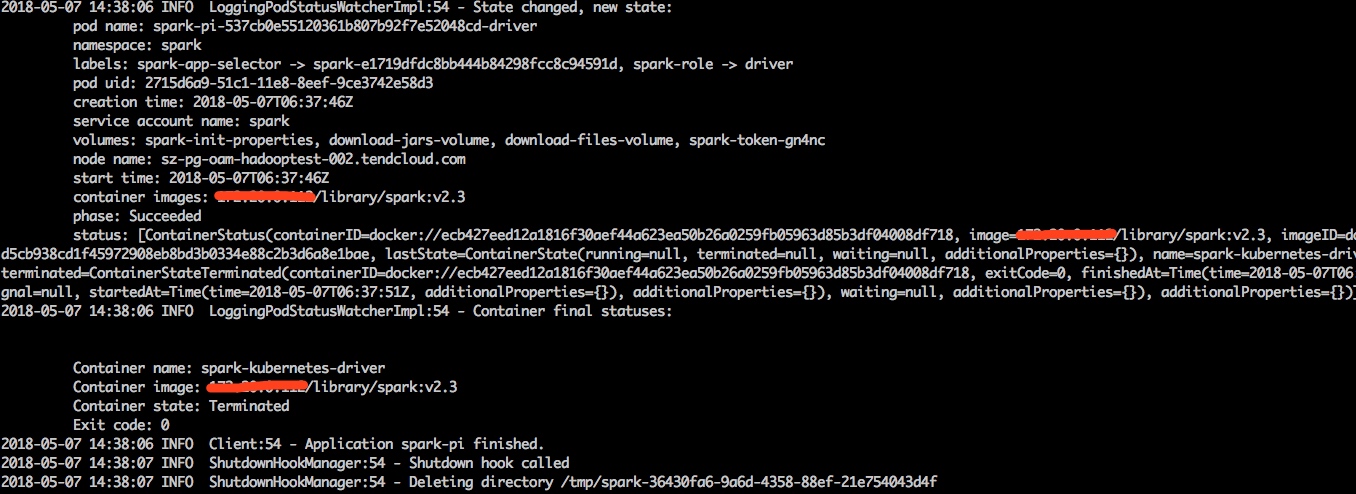
任务结束,会输出:
访问Spark Driver UI
我们可以在本地使用kubectl port-forward访问Driver UI:
$ kubectl port-forward <driver-pod-name> 4040:4040
执行完后通过http://localhost:4040访问。
访问日志
Spark的所有日志都可以通过Kubernetes API和kubectl CLI进行访问:
$ kubectl -n=<namespace> logs -f <driver-pod-name>
如何实现租户和资源隔离
Kubernetes Namespace
在Kubernetes中,我们可以使用namespace在多用户间实现资源分配、隔离和配额。Spark On Kubernetes同样支持配置namespace创建Spark作业。
首先,创建一个Kubernetes namespace:
$ kubectl create namespace spark
由于我们的Kubernetes集群使用了RBAC,所以还需创建serviceaccount和绑定role:
$ kubectl create serviceaccount spark -n spark
$ kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark:spark --namespace=spark
并在spark-submit中新增以下配置:
$ bin/spark-submit \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.kubernetes.namespace=spark \
...
资源隔离
考虑到我们Spark作业的一些特点和计算资源隔离,前期我们还是选择了较稳妥的物理隔离方案。具体做法是为每个组提供单独的Kubernetes namespace,计算任务都在各自namespace里提交。计算资源以物理机为单位,折算成cpu和内存,纳入Kubernetes统一管理。在Kubernetes集群里,通过node label和PodNodeSelector将计算资源和namespace关联。从而实现在提交Spark作业时,计算资源总是选择namespace关联的node。
具体做法如下:
1、创建node label
$ kubectl label nodes <node_name> spark:spark
2、开启Kubernetes admission controller
我们是使用kubeadm安装Kubernetes集群,所以修改/etc/kubernetes/manifests/kube-apiserver.yaml,在--admission-control后添加PodNodeSelector
$ cat /etc/kubernetes/manifests/kube-apiserver.yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
creationTimestamp: null
labels:
component: kube-apiserver
tier: control-plane
name: kube-apiserver
namespace: kube-system
spec:
containers:
- command:
- kube-apiserver
- --secure-port=6443
- --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
- --admission-control=Initializers,NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,PodNodeSelector
...
3、配置PodNodeSelector
在namespace的annotations中添加scheduler.alpha.kubernetes.io/node-selector: spark=spark。
apiVersion: v1
kind: Namespace
metadata:
annotations:
scheduler.alpha.kubernetes.io/node-selector: spark=spark
name: spark
完成以上配置后,可以通过spark-submit测试结果:
$ spark-submit
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark
--conf spark.kubernetes.namespace=spark
--master k8s://https://xxxx:6443
--deploy-mode cluster
--name spark-pi
--class org.apache.spark.examples.SparkPi
--conf spark.executor.instances=5
--conf spark.kubernetes.container.image=xxxx/library/spark:v2.3
http://xxxx:81/spark-2.3.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.3.0.jar

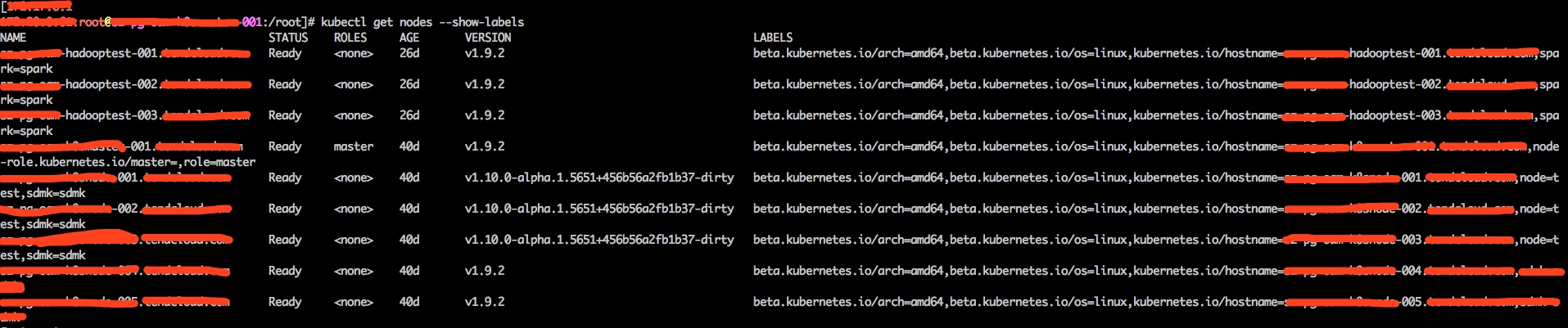
我们可以看到,Spark作业全分配到了关联的hadooptest-001到003三个node上。
待解决问题
Kubernetes HA
Kubernetes的集群状态基本都保存在etcd中,所以etcd是HA的关键所在。由于我们目前还处在半生产状态,HA这方面未过多考虑。有兴趣的同学可以查看:https://kubernetes.io/docs/setup/independent/high-availability/。
日志
在Spark On Yarn下,可以开启yarn.log-aggregation-enable将日志收集聚合到HDFS中,以供查看。但是在Spark On Kubernetes中,则缺少这种日志收集机制,我们只能通过Kubernetes pod的日志输出,来查看Spark的日志:
$ kubectl -n=<namespace> logs -f <driver-pod-name>
收集和聚合日志,我们后面会和ES结合。
监控
我们TalkingData内部有自己的监控平台OWL(已开源),未来我们计划编写metric plugin,将Kubernetes接入OWL中。
混合部署
为了保证Spark作业时刻有可用的计算资源,我们前期采用了物理隔离的方案。显而易见,这种方式大幅降低了物理资源的使用率。下一步我们计划采用混部方案,通过以下三种方式实现:
- 将HDFS和Kubernetes混合部署
- 为Spark作业和Kubernetes node划分优先级,在低优先级的node上同时运行一些无状态的其他生产服务
- 利用云实现资源水平扩展,以防止资源突增
资源扩展
在采用以下两种方法增加资源使用率时,集群可能会面临资源短缺和可用性的问题:
- 混合部署
- 资源超卖
这会导致运行资源大于实际物理资源的情况(我称之为资源挤兑)。一种做法是给资源划分等级,优先保证部分等级的资源供给。另一种做法是实现资源的水平扩展,动态补充可用资源,并在峰值过后自动释放。我在另一篇文章中阐述了这种设计理念:https://xiaoxubeii.github.io/articles/k8s-on-cloud/。
TalkingData有自研的多云管理平台,我们的解决方法是实现单独的Kubernetes tdcloud-controller-manager作为资源的provider和manager,通过TalkingData OWL监控告警,实现资源的水平扩展。
Q&A
Q:我想问权限方面的问题,前面有看到一个提交作业的例子是spark-summit –files hdfs://host:port/path/to/file1,即用spark处理hdfs上的数据,出于数据安全的考虑,hdfs一般会开启权限认证,用户在kerberos上做认证,用同一个身份信息访问spark和hdfs。对于spark on k8s 这样一个方案,是如何认证并与hdfs结合的呢?
A:老实说,我们原生的Spark集群也还是基于POSIX,并没有使用kerberos。不过我认为一个可行的结合方案是使用Kubernetes的webhook,在作业提交时,和kerberos交互换取身份验证信息。具体可参考:https://kubernetes.io/docs/admin/authorization/webhook/。
Q:为什么使用node label进行资源隔离,而不使用resourcequota对多租户进行资源隔离? A:由于我们很多大数据计算作业对SLA有很高的要求,并且Docker实际上对很多应用的资源限制都支持的不好。所以我们前期为了稳妥,还是对计算资源进行了物理隔离。
Q:除了日志无法聚合外,每次查看Driver UI也是个问题。比如当我跑的程序较多时怎么有效地管理这些completed driver pod? A:是的,Spark On Kubernetes还缺少应用管理的功能。不过这个功能已经列在官方的todo list里。
Q:比如flannel是把flannel参数传给docker,一种用cni插件,他们有何差别? A:实际上cni是Kubernetes的标准网络接口,而flannel是实现pod间通信的网络插件。cni中有两类插件:一个是ipam,一个是network plugins。flannel属于后者,是可以纳入cni管理的。
Q:这里的多租户隔离,只提到任务执行过程的调度,那对于不同租户的任务提交,状态监控,结果呈现如何实现隔离的? A:不同的租户对应不同的Kubernetes namespace,所以自然实现了任务提交和状态监控的隔离。至于计算结果,我们以往是单纯用hdfs path做隔离。我们目前内部有大数据平台,那里真正实现了多租户。
Q:spark on kubernetes这种方式为开发人员增加了难度,不像其他的集群方案,开发人员除了要会 spark还要会kubernetes,请问怎么推? A:实际上Spark On Kubernetes对大数据开发人员是透明的,任务的提交方式并没有改变,只是加了一些额外的option。并且我们上层是有统一的大数据平台,进行作业提交。
Q:在使用hdfs存储资源下,如果不使用spark的数据本地性,大量数据之间的传输,map和reduce操作是否会影响spark的计算性能呢? A:个人认为肯定会有影响,因为每次从hdfs读取,会带来巨大的网络流量。但是我本身对spark的数据本地性没有什么研究。后期我们计划将hdfs和Kubernetes混部,将数据尽量靠近计算节点,不知道这种方式能否缓解这个问题。同时,我们还可以使用Spark on Kubernetes的external-shuffle-service,从而使用hostpath volume将shuffle和executor pods打通。
Q:spark会作为哪种资源部署方式部署?deployment还是statefulSet?或者其他?sprk在生产环境上部署有需要什么资源配置?能否分享下talkingdata的生产环境是如何分配spark资源的? A:Spark On Kubernetes实际就是创建了Spark driver headless service,然后创建Spark driver pod,最后由driver创建executors pods。上述分享中我也提到了,目前我们还是以物理机作为spark资源分配的单位。
Q:yarn vs k8s优缺点 A:我们以前的Spark就是采用Spark On Yarn的方式,不过我对Yarn不是非常了解。之所以采用k8s是因为,我们想统一底层的资源调度平台。但是Yarn目前还是和Hadoop生态强耦合的。